BLOG
Architecture, engineering, and operational intelligence for production LLM systems.
Featured

Why Your AI Agents Need a Unified LLM Gateway
Running multiple LLM providers without a gateway is like operating a fleet with no dispatch. Here's how SpiderGate V2 unifies access, enforces budgets, and gives every agent a single endpoint.

How AI Automation Agencies Save Money with SpiderGate BYOK
Evaluating Gateway Latency Overhead
Securing LLM API Keys at the Edge
All Articles
How AI Automation Agencies Save Money with SpiderGate BYOK
Discover how shifting to a BYOK model with SpiderGate can eliminate inference overhead and maximize profit margins for your AI agency.
Evaluating Gateway Latency Overhead
Adding a hop in your LLM request path adds latency. But how much? We dive into the benchmarks.
Securing LLM API Keys at the Edge
Shipping API keys to the client is a disaster. Explore why you need a gateway to secure your LLM API keys at the edge.
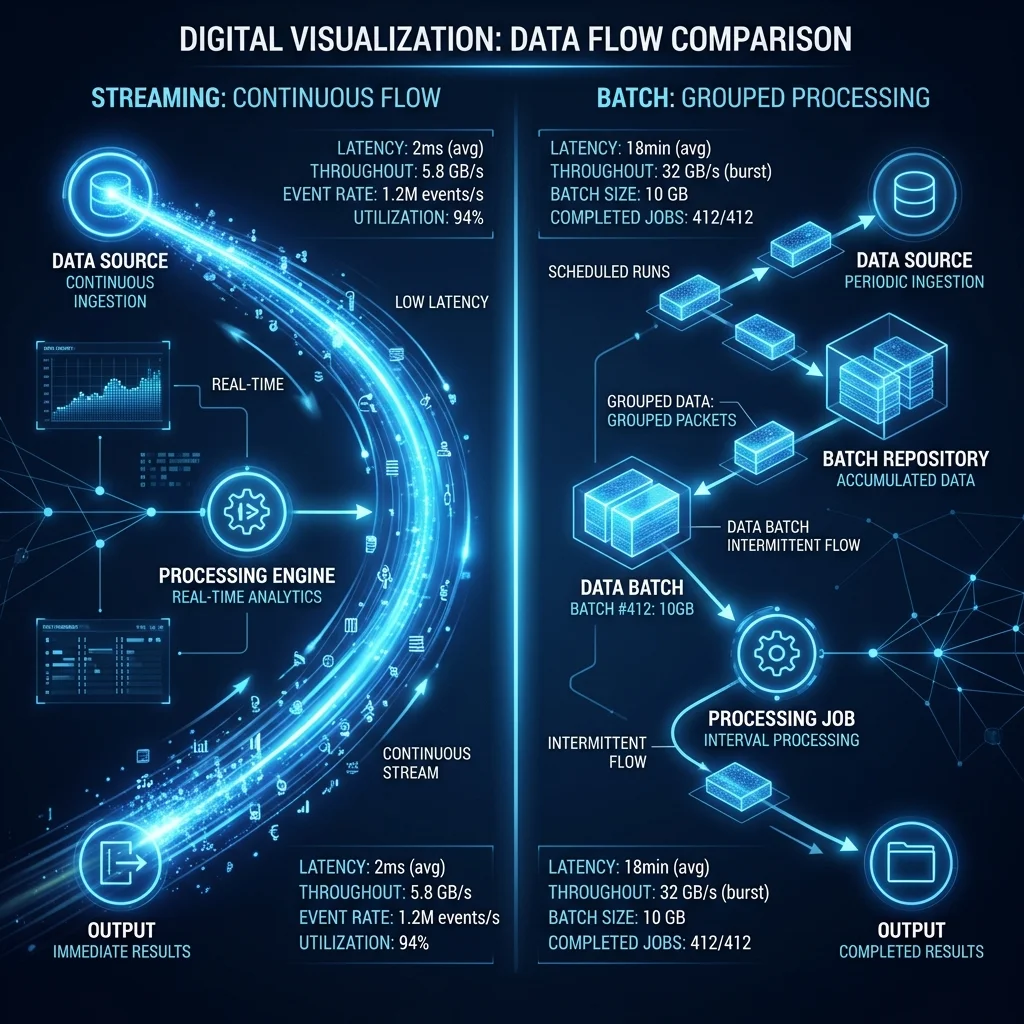
Streaming vs. Batch: Choosing the Right LLM Delivery Mode for Your Agents
Not every agent needs real-time streaming. SpiderGate's delivery mode system lets you choose between streaming, batch, and hybrid modes per agent — optimizing for cost, latency, or throughput.

Multi-Tenant Isolation: Running 50 Teams Through One Gateway Safely
When every team shares the same LLM gateway, data leakage isn't just a risk — it's an inevitability without proper isolation. Here's how SpiderGate enforces tenant boundaries at every layer.

Prompt Caching at Scale: How SpiderGate Reduces Redundant LLM Calls by 40%
Your agents are asking the same questions hundreds of times per hour. SpiderGate's semantic prompt cache detects near-duplicate requests and serves cached responses, cutting costs and latency simultaneously.

Rate Limiting for AI Agents: Why Token Buckets Beat Simple Throttling
Simple rate limiting kills agent performance. SpiderGate's adaptive token bucket algorithm balances throughput with fair resource allocation across hundreds of concurrent agents.

Fallback Chains: Designing Resilient Multi-Provider LLM Pipelines
When your primary LLM provider goes down at 3 AM, your agents shouldn't stop working. SpiderGate's fallback chain system automatically routes to backup providers with zero application changes.

Budget Guardrails: How SpiderGate Prevents LLM Cost Overruns
One misconfigured agent can drain your entire monthly LLM budget in hours. SpiderGate's budget guardrail system enforces per-agent, per-model, and per-team spending limits in real time.

Per-Agent Observability: Tracing Every Token Through the Gateway
When 50 agents share the same LLM gateway, who's burning the budget? SpiderGate's tracing system tags every request with agent identity, task type, and brand — giving you full-stack LLM observability.

Task-Based Routing: How SpiderGate Maps Intent to Models
Not every prompt needs GPT-4o. SpiderGate's alias system lets you define routing by task — 'fast', 'smart', 'code' — and the gateway resolves to the optimal provider in real time.
Why Your AI Agents Need a Unified LLM Gateway
Running multiple LLM providers without a gateway is like operating a fleet with no dispatch. Here's how SpiderGate V2 unifies access, enforces budgets, and gives every agent a single endpoint.